Các công ty công nghệ đo lường tác động của AI đối với phát triển phần mềm như thế nào
(newsletter.pragmaticengineer.com)- Trong bối cảnh các công cụ lập trình AI được triển khai rộng rãi và chi phí gia tăng, nhiều công ty công nghệ lớn đã hệ thống hóa cách định lượng hiệu quả thực tế của AI bằng bộ chỉ số nhiều tầng
- Cốt lõi là cách tiếp cận kết hợp theo dõi đồng thời các chỉ số nền tảng kỹ thuật hiện có (ví dụ: PR throughput, change failure rate) và các chỉ số chuyên biệt cho AI (ví dụ: tỷ lệ sử dụng AI, thời gian tiết kiệm được, CSAT)
- Nhấn mạnh tư duy thực nghiệm nhằm rút ra xu hướng và tương quan thông qua phân rã theo mức độ sử dụng AI ở cấp nhóm/cá nhân/cohort và so sánh trước-sau
- Cần một thiết kế cân bằng để giám sát liên tục chất lượng, khả năng bảo trì và trải nghiệm nhà phát triển cùng với các chỉ số tốc độ, nhằm ngăn nợ kỹ thuật gia tăng và tác dụng ngược của lợi ích ngắn hạn
- Về dài hạn, việc đo lường được dự báo sẽ mở rộng sang telemetry từ agent từ xa và cả các không gian công việc không phải lập trình; rốt cuộc câu hỏi sẽ quy về: liệu AI có đang làm tốt hơn những điều vốn đã quan trọng (chất lượng, tốc độ ra mắt thị trường, trải nghiệm nhà phát triển) hay không
Diễn ngôn về tác động của AI và khoảng trống trong đo lường
- Như thường thấy trên LinkedIn và nhiều nơi khác, các tuyên bố rằng AI đang thay đổi cách doanh nghiệp phát triển phần mềm đang xuất hiện dày đặc
- Liên tiếp có các bài viết cho biết khối lượng mã AI quy mô lớn như Google 25%, Microsoft 30% thực sự được triển khai thành mã production
- Trong khi một số nhà sáng lập cho rằng AI có thể thay thế kỹ sư junior, thì nghiên cứu của METR lại cho thấy khả năng bóp méo cảm nhận về thời gian và làm giảm năng suất
- Truyền thông thường đơn giản hóa tác động của AI thành “đã viết được bao nhiêu mã”, nhưng hệ quả là ngành đang đối mặt với nguy cơ tích lũy nợ kỹ thuật lớn nhất từ trước đến nay
- Dù đã có đồng thuận rằng LOC (số dòng mã) không phù hợp làm chỉ số năng suất, nó vẫn nổi lên trở lại vì dễ đo lường, qua đó che khuất các giá trị cốt lõi như chất lượng, đổi mới, tốc độ phát hành và độ tin cậy
- Hiện nay, nhiều lãnh đạo kỹ thuật đang đưa ra những quyết định quan trọng về công cụ AI mà chưa thực sự biết rõ điều gì hiệu quả và điều gì không
- Theo LeadDev’s 2025 AI Impact Report, 60% lãnh đạo cho rằng ‘thiếu chỉ số rõ ràng’ là thách thức lớn nhất
- Các lãnh đạo ở hiện trường cảm thấy bất mãn giữa áp lực thành tích và ban điều hành ám ảnh với LOC, còn khoảng cách giữa thông tin cần có và thứ thực tế được đo lường ngày càng nới rộng
- Tác giả đã nghiên cứu công cụ dành cho nhà phát triển hơn 10 năm, và từ sau năm 2021 đã tư vấn về cải thiện năng suất và đo lường tác động của AI
- Sau khi gia nhập với vai trò DX CTO, tác giả đã hợp tác với hàng trăm doanh nghiệp để dẫn dắt phân tích về DevEx, hiệu quả và ảnh hưởng của AI
- Đầu năm 2025, tác giả đồng chấp bút AI Measurement Framework dựa trên dữ liệu của hơn 400 công ty
- Đây là bộ chỉ số khuyến nghị cần thiết để đo lường việc áp dụng và tác động của AI, được xây dựng dựa trên nghiên cứu thực địa và phân tích dữ liệu
- Trong bài viết này, tác giả xem xét cách 18 công ty công nghệ thực tế đo lường tác động của AI, đồng thời
- chia sẻ các ví dụ chỉ số thực tế từ Google, GitHub, Microsoft
- cách vận dụng để xác định điều gì thực sự hiệu quả
- phương pháp luận đo lường tác động của AI
- định nghĩa và hướng dẫn về các chỉ số tác động của AI
1. Các chỉ số đo lường thực tế của 18 công ty
- Chia sẻ hình ảnh tổng hợp case study của 18 công ty như Google, GitHub, Microsoft, Dropbox, Monzo, Atlassian, Adyen, Booking.com, Grammarly
- Dù mỗi công ty có cách tiếp cận khác nhau, họ đều tập trung vào một số nhóm chỉ số cốt lõi
-
1. Chỉ số sử dụng (Adoption & Usage)
- DAU/WAU/MAU: gần như mọi công ty đều theo dõi số người dùng hoạt động theo ngày/tuần/tháng của công cụ AI
- Cường độ sử dụng/sự kiện sử dụng: Google, eBay và một số công ty khác phân tách chi tiết đến mức viết mã, phản hồi chat, thậm chí cả agentic actions
- AI tool CSAT: nhiều công ty như Dropbox, Webflow, Grammarly cũng đồng thời khảo sát mức độ hài lòng
-
2. Chỉ số năng suất (Throughput & Time Savings)
- PR throughput: nhiều công ty như GitHub, Dropbox, Webflow, CircleCI cùng theo dõi chỉ số này
- Time savings: đo thời gian tiết kiệm được mỗi tuần theo từng kỹ sư (Dropbox, Monzo, Toast, Xero...)
- PR cycle time: được Microsoft, CircleCI, Xero, Grammarly sử dụng
-
3. Chỉ số chất lượng/độ ổn định (Quality & Reliability)
- Change Failure Rate: là chỉ số chất lượng phổ biến nhất tại GitHub, Dropbox, Adyen, Booking.com, Webflow...
- Nhận thức về khả năng bảo trì/chất lượng mã: GitHub, Adyen, CircleCI... đánh giá chỉ số này gắn với DevEx
- Tỷ lệ lỗi/tỷ lệ hoàn tác: Glassdoor (số lỗi), Toast (PR revert rate)
-
4. Chỉ số trải nghiệm nhà phát triển (Developer Experience)
- Mức độ hài lòng/khảo sát nhà phát triển (DevEx, DXI): được Atlassian, Webflow, CarGurus, Vanguard... sử dụng
- Bad Developer Days (BDD): Microsoft đo ma sát theo cách riêng bằng khái niệm ‘một ngày làm việc tồi tệ của nhà phát triển’
- Tải nhận thức và ma sát của nhà phát triển: Google, eBay...
-
5. Chỉ số chi phí và đầu tư (Spend & ROI)
- Chi tiêu cho AI (tổng & theo từng nhà phát triển): một số công ty như Dropbox, Grammarly, Shopify cũng theo dõi chi phí
- Capacity worked (mức độ tận dụng): Glassdoor đo lường công cụ đã được dùng đến mức nào so với tiềm năng tối đa
-
6. Chỉ số đổi mới/thử nghiệm (Innovation & Experimentation)
- Innovation ratio / velocity: GitHub, Microsoft, Webflow... lượng hóa tốc độ đổi mới thành chỉ số
- Số lượng A/B test: Glassdoor xem số A/B test hàng tháng là một chỉ số cốt lõi
- Họ theo dõi song song các chỉ số kết quả như thời gian tiết kiệm được, PR throughput, change failure rate, số người dùng tham gia, tỷ lệ đổi mới và các chỉ số hành vi sử dụng
- Tùy theo mức độ ưu tiên của từng tổ chức và bối cảnh sản phẩm, cấu hình chỉ số sẽ khác nhau; không có một chỉ số vạn năng duy nhất
2. Nền tảng vững chắc: cốt lõi của việc đo lường tác động AI
- Việc viết code bằng AI không làm thay đổi tiêu chuẩn của phần mềm tốt. Chất lượng, khả năng bảo trì và tốc độ vẫn là các yếu tố cốt lõi
- Vì vậy, các chỉ số hiện có như Change Failure Rate, PR throughput, PR cycle time, trải nghiệm nhà phát triển (DevEx) vẫn rất quan trọng
- Không cần các chỉ số hoàn toàn mới
- Câu hỏi quan trọng là: “AI có đang giúp cải thiện những thứ vốn dĩ đã quan trọng hay không?”
- Nếu chỉ dừng ở các chỉ số bề mặt như LOC hay tỷ lệ chấp nhận, sẽ không thể nắm đúng tác động của AI
- Cần các chỉ số mục tiêu mới để hiểu chính xác điều gì đang diễn ra trong việc sử dụng AI
- Có thể nắm được AI đang được dùng ở đâu, nhiều đến mức nào và theo cách nào để phục vụ các quyết định như ngân sách, rollout công cụ, bảo mật và compliance
- Các chỉ số AI cho thấy những điều như sau:
- Có bao nhiêu nhà phát triển và kiểu nhà phát triển nào đang áp dụng công cụ AI?
- AI đang tác động đến bao nhiêu công việc và những loại công việc nào?
- Chi phí là bao nhiêu?
- Các chỉ số kỹ thuật cốt lõi cho thấy những điều như sau:
- Đội ngũ có đang ship nhanh hơn không
- Chất lượng và độ tin cậy đang tăng hay giảm
- Khả năng bảo trì mã có đang suy giảm không
- Các công cụ AI có đang giảm ma sát trong workflow của nhà phát triển không
-
Xét trường hợp của Dropbox
- Chỉ số AI
- DAU/WAU (người dùng hoạt động hằng ngày/hằng tuần)
- CSAT của công cụ AI (mức độ hài lòng)
- Thời gian tiết kiệm trên mỗi kỹ sư
- Chi tiêu cho AI
- Chỉ số cốt lõi (áp dụng Core 4 Framework)
- Change Failure Rate
- PR throughput
- Kết quả
- Người dùng AI thường xuyên hằng tuần = 90% tổng số kỹ sư (cao hơn mức trung bình ngành là 50%)
- Người dùng AI thường xuyên có số PR được merge tăng 20% + Change Failure Rate giảm
- Điều cốt lõi không phải là tỷ lệ áp dụng tự thân, mà là xác nhận liệu AI có đang đóng góp thực chất vào hiệu quả ở cấp tổ chức, đội nhóm và cá nhân hay không
- Chỉ số AI
3. Phân rã chỉ số theo mức độ sử dụng AI
- Thực hiện nhiều phân tích so sánh để hiểu AI đang thay đổi cách nhà phát triển làm việc như thế nào
- So sánh người dùng AI với người không dùng AI
- So sánh các chỉ số kỹ thuật cốt lõi trước và sau khi áp dụng công cụ AI
- Theo dõi cùng một nhóm người dùng (cohort analysis) để quan sát thay đổi sau khi áp dụng AI
- Phân tách dữ liệu (slicing & dicing) để rút ra mẫu hình
- Phân tích theo các thuộc tính như vai trò, thâm niên, khu vực, ngôn ngữ chính
- Ví dụ: nhân sự junior tăng số lượng PR tạo ra, còn senior chậm lại do tỷ trọng review tăng lên
- Qua đó có thể xác định những nhóm cần thêm đào tạo và hỗ trợ cũng như những nhóm đạt hiệu quả lớn khi dùng AI
- Trường hợp của Webflow
- Trong nhóm nhà phát triển có thâm niên từ 3 năm trở lên, hiệu quả tiết kiệm thời gian khi dùng AI là lớn nhất
- Khi dùng các công cụ như Cursor, Augment Code, PR throughput tăng 20% (so sánh người dùng AI với người không dùng)
- Sự cần thiết của baseline vững chắc
- Các tổ chức không có nền tảng chỉ số năng suất của nhà phát triển sẽ khó đo lường tác động của AI
- Có thể nhanh chóng thiết lập baseline bằng Core 4 Framework (được Dropbox, Adyen, Booking.com... sử dụng)
- Tham khảo mẫu và hướng dẫn
- Kết hợp dữ liệu hệ thống, dữ liệu lấy mẫu trải nghiệm và khảo sát định kỳ để thực hiện so sánh có độ tin cậy cao
- Theo dõi liên tục và tư duy thử nghiệm là cốt lõi
- Đo lường một lần là không có nhiều ý nghĩa; cần theo dõi chuỗi thời gian để nắm xu hướng và mẫu hình
- Điểm chung của các công ty thành công: đặt mục tiêu cụ thể và kiểm chứng giả thuyết bằng dữ liệu
- Không phụ thuộc mù quáng vào dữ liệu, mà duy trì mindset thử nghiệm định hướng mục tiêu
4. Cảnh giác với khả năng bảo trì, chất lượng và trải nghiệm nhà phát triển
- Phát triển có hỗ trợ AI vẫn là một lĩnh vực còn mới
- Vẫn thiếu dữ liệu chứng minh tác động đối với chất lượng mã và khả năng bảo trì trong dài hạn
- Bài toán cốt lõi là cân bằng giữa việc tăng tốc trong ngắn hạn và rủi ro nợ kỹ thuật trong dài hạn
- Cần theo dõi đồng thời các chỉ số đối trọng lẫn nhau
- Phần lớn doanh nghiệp theo dõi đồng thời Change Failure Rate và PR throughput
- Nếu tốc độ tăng nhưng chất lượng giảm, đó sẽ là tín hiệu cảnh báo vấn đề ngay lập tức
- Các chỉ số bổ sung để giám sát chất lượng và khả năng bảo trì
- Change confidence: mức độ tự tin của nhà phát triển vào độ ổn định của mã khi triển khai
- Code maintainability: mức độ dễ hiểu và dễ chỉnh sửa của mã
- Perception of quality: nhận thức của nhà phát triển về chất lượng mã và thực hành của cả đội
- Cần kết hợp chỉ số hệ thống với chỉ số tự báo cáo
- Dữ liệu hệ thống: PR throughput, tần suất triển khai...
- Dữ liệu tự báo cáo: mức độ tự tin khi thay đổi, khả năng bảo trì... → tín hiệu then chốt để ngăn tác động tiêu cực dài hạn
- Khuyến nghị khảo sát trải nghiệm nhà phát triển (DevEx) định kỳ
- Có thể theo dõi tương quan giữa chất lượng, khả năng bảo trì và việc dùng AI thông qua ví dụ khảo sát
- Phản hồi phi cấu trúc cũng hữu ích để nhận diện vấn đề hiện hữu và thảo luận giải pháp
- Ý nghĩa thực sự của trải nghiệm nhà phát triển (DevEx)
- Không phải là khái niệm phúc lợi kiểu “bóng bàn và bia”, mà là loại bỏ ma sát trong toàn bộ quá trình phát triển
- Mục tiêu là bảo đảm hiệu quả xuyên suốt toàn bộ quy trình từ lập kế hoạch → phát triển → kiểm thử → triển khai → vận hành
- Công cụ AI có thể giảm ma sát ở khâu viết mã và kiểm thử, nhưng cũng có nguy cơ tạo ra ma sát mới ở review, ứng phó sự cố và bảo trì
- Insight từ thực tế (Shelly Stuart của CircleCI)
- Chỉ số đầu ra (PR throughput) cho thấy điều gì đang xảy ra, nhưng mức độ hài lòng của nhà phát triển cho thấy tính bền vững
- Việc áp dụng AI có thể gây bất tiện ban đầu, vì vậy theo dõi mức độ hài lòng là công cụ cốt lõi để phân biệt ma sát ngắn hạn và giá trị dài hạn
- 75% doanh nghiệp theo dõi đồng thời CSAT/mức độ hài lòng với công cụ AI → tập trung vào việc xây dựng văn hóa phát triển bền vững hơn là chỉ tốc độ
5. Các chỉ số độc đáo và xu hướng thú vị
- Microsoft: Bad Developer Day (BDD)
- Khái niệm đo lường theo thời gian thực mức độ ma sát và mệt mỏi trong công việc hằng ngày
- Các yếu tố khiến một ngày trở nên tồi tệ gồm ứng phó sự cố và xử lý tuân thủ, chi phí chuyển đổi giữa họp và email, thời gian tiêu tốn cho các hệ thống quản lý công việc
- Cân bằng với hoạt động PR (chỉ dấu thay thế cho thời gian coding), và đánh giá là một ngày tốt nếu vẫn đảm bảo được một khoảng thời gian nhất định cho coding dù có một số công việc giá trị thấp
- Mục tiêu: xác định xem các công cụ AI có đang làm giảm tần suất và mức độ nghiêm trọng của BDD hay không
- Glassdoor: Đo lường thử nghiệm và tỷ lệ sử dụng công cụ
- Theo dõi việc AI có tăng tốc đổi mới và thử nghiệm hay không thông qua số lượng A/B test hằng tháng
- Đồng thời triển khai chiến lược nuôi dưỡng power user thành những người truyền bá AI nội bộ
- Capacity worked (tỷ lệ sử dụng): đo lường mức sử dụng thực tế so với mức sử dụng tiềm năng của công cụ để xác định thời điểm bão hòa triển khai và quyết định tái phân bổ ngân sách
- Sự suy giảm của Acceptance Rate
- Trước đây là chỉ số AI cốt lõi, nhưng phạm vi hẹp vì chỉ nhìn vào thời điểm đề xuất được chấp nhận
- Không phản ánh được khả năng bảo trì, phát sinh bug, hoàn tác mã nguồn, hay năng suất mà developer cảm nhận
- Hiện không còn thường được dùng làm chỉ số cấp cao nhất, nhưng vẫn có ngoại lệ:
- GitHub: dùng cho việc cải thiện Copilot và ra quyết định sản phẩm
- T-Mobile: ước tính mức độ mã do AI tạo ra thực sự được đưa vào production
- Atlassian: dùng làm chỉ số bổ trợ cho mức độ hài lòng của developer và chất lượng đề xuất
- Phân tích chi phí và đầu tư
- Phần lớn doanh nghiệp không chủ động theo dõi chặt chi phí sử dụng để tránh làm developer chùn bước
- Shopify áp dụng cách dùng AI Leaderboard để chúc mừng các developer có mức tiêu thụ token cao
- ICONIQ 2025 State of AI Report: dự báo ngân sách năng suất AI trong doanh nghiệp năm 2025 sẽ tăng gấp đôi so với 2024
- Một số nơi đang chuyển sang giảm ngân sách tuyển dụng và tái phân bổ sang ngân sách cho công cụ AI
- Sự thiếu vắng telemetry cho agent
- Hiện gần như chưa có đo lường, nhưng khả năng được triển khai trong vòng 12 tháng tới là cao
- Khi workflow agent tự chủ lan rộng, nhu cầu đo lường hành vi, độ chính xác, tỷ lệ hồi quy sẽ tăng lên
- Thiếu đo lường cho các hoạt động không phải coding
- Hiện chủ yếu chỉ giới hạn ở hỗ trợ viết code; các phiên lập kế hoạch bằng ChatGPT hay xử lý issue trên Jira thường chưa được đưa vào đầy đủ
- Đến năm 2026, việc sử dụng AI sẽ mở rộng trên toàn bộ các giai đoạn của SDLC, nên cách đo lường cũng cần tiến hóa theo
- Các hoạt động cụ thể như code review hay kiểm tra lỗ hổng thì dễ đo lường, còn các công việc trừu tượng thì khó hơn
- Dự kiến sẽ mở rộng phạm vi của các phép đo tự khai báo ("Tuần này AI đã giúp bạn tiết kiệm bao nhiêu thời gian?")
6. Nên đo lường tác động của AI như thế nào?
- AI Measurement Framework
- Được phát triển cùng Abi Noda, đồng tác giả của DevEx Framework
- Được xây dựng dựa trên dữ liệu thực tế từ hơn 400 doanh nghiệp và hơn 10 năm nghiên cứu về năng suất developer
- Kết hợp các chỉ số AI và chỉ số cốt lõi để cùng đánh giá tốc độ, chất lượng, khả năng bảo trì và trải nghiệm developer (DevEx)
- Một chỉ số đơn lẻ (ví dụ: tỷ lệ code do AI tạo ra) phù hợp để làm headline, nhưng không phải là công cụ đo hiệu quả đủ đầy
- Cần kết hợp dữ liệu định tính và định lượng
- Chỉ khi thu thập cả chỉ số hệ thống (PR throughput, DAU/WAU, tần suất triển khai, v.v.) lẫn chỉ số tự khai báo (CSAT, thời gian tiết kiệm được, nhận thức về khả năng bảo trì, v.v.) mới có thể hiểu được bức tranh đa chiều
- Nhiều doanh nghiệp dùng DX để thu thập và trực quan hóa dữ liệu, nhưng cũng có thể tự xây hệ thống tùy chỉnh
- Phương pháp thu thập dữ liệu
- Dữ liệu hệ thống (định lượng): API quản trị của công cụ AI (mức sử dụng, chi tiêu, token, tỷ lệ chấp nhận) + các chỉ số từ SCM, JIRA, CI/CD, build, quản lý sự cố
- Khảo sát định kỳ (định tính): khảo sát theo quý hoặc nửa năm để nắm bắt xu hướng dài hạn như DevEx, mức độ hài lòng, độ tin cậy của thay đổi, khả năng bảo trì — những yếu tố khó lấy từ chỉ số hệ thống
- Lấy mẫu trải nghiệm (định tính): chèn các câu hỏi ngắn trong workflow (ví dụ: ngay sau khi gửi PR, hỏi "Bạn có dùng AI không?", "Đoạn code này có dễ hiểu không?")
- Ưu tiên triển khai
- Khảo sát định kỳ là điểm khởi đầu nhanh nhất: có thể thu được dữ liệu ban đầu trong vòng 1–2 tuần
- Cũng như độ chính xác cần thiết khi treo rèm khác với khi phóng tên lửa, các quyết định kỹ thuật vẫn có ý nghĩa ngay cả khi mức chính xác chỉ đủ để đưa ra định hướng
- Sau đó, kết hợp thêm các phương pháp thu thập dữ liệu khác để đối chiếu chéo sẽ làm tăng độ tin cậy
- Tài nguyên bổ sung
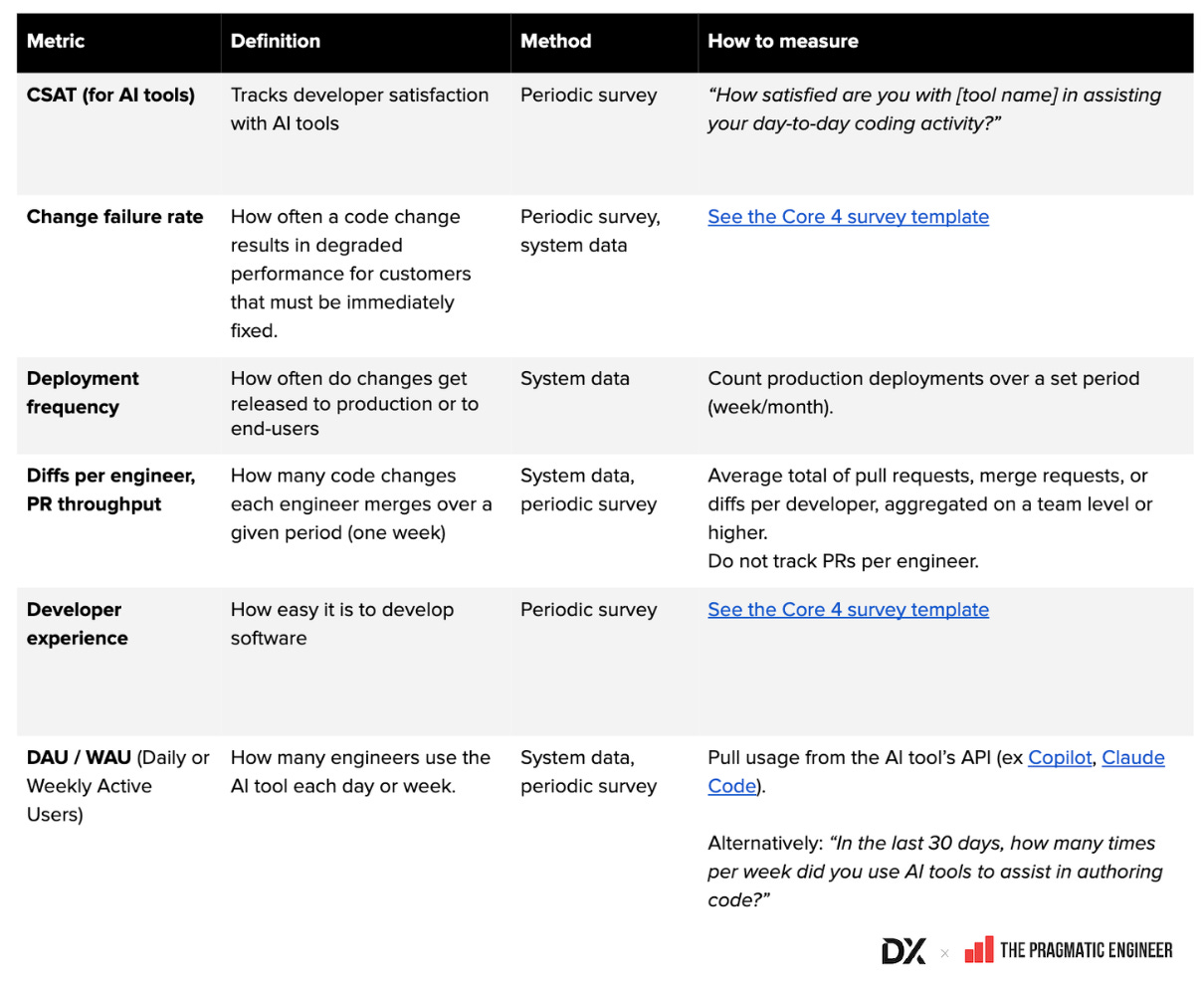
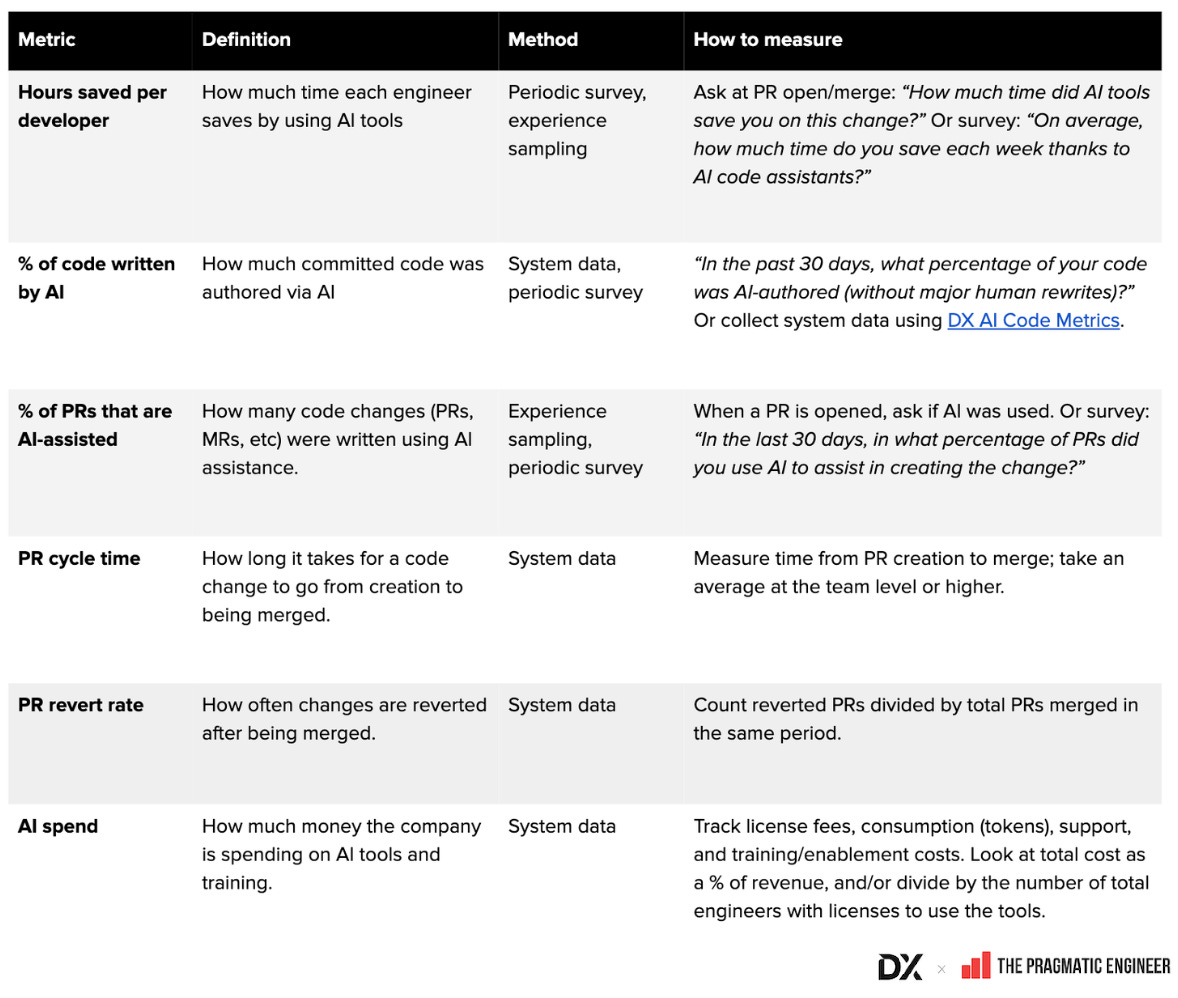
- Bảng thuật ngữ các chỉ số AI phổ biến (Google Sheet): tổng hợp định nghĩa, cách tính và phương pháp thu thập
- Hình ảnh ví dụ về các chỉ số AI và năng suất developer
- Những điểm cần cân nhắc khi áp dụng nội bộ
- Thay vì chạy theo tỷ lệ chấp nhận hay một chỉ số đơn lẻ, cần xác nhận xem năng lực đưa phần mềm chất lượng cao đến tay khách hàng một cách nhanh chóng có được cải thiện hay không
- Câu hỏi cốt lõi:
> “AI có đang làm cho những điều vốn đã quan trọng (chất lượng, tốc độ phát hành, trải nghiệm developer) trở nên tốt hơn không?” - Các câu hỏi cần được thảo luận trong cuộc họp lãnh đạo:
- Tổ chức của chúng ta định nghĩa hiệu quả kỹ thuật như thế nào?
- Chúng ta đã có dữ liệu hiệu quả trước khi triển khai công cụ AI chưa? Nếu chưa, sẽ nhanh chóng thiết lập baseline bằng cách nào?
- Chúng ta có đang nhầm lẫn hoạt động AI với tác động AI hay không?
- Chúng ta có đang cân bằng giữa tốc độ, chất lượng và khả năng bảo trì không?
- Tác động lên trải nghiệm developer có đang được thể hiện không?
- Chúng ta có đang vận hành phương thức đo lường đa tầng bao gồm cả dữ liệu hệ thống và dữ liệu tự khai báo không?
{kind=link}
{kind=link}
7. Cách Monzo đo lường tác động của AI
- Giai đoạn đầu triển khai
- Công cụ đầu tiên là GitHub Copilot. Được bao gồm trong giấy phép GitHub và tích hợp tự nhiên vào VS Code nên tất cả kỹ sư đều bắt đầu sử dụng
- Sau đó tiếp tục đầu tư xoay quanh Copilot, đồng thời thử nghiệm song song nhiều công cụ khác nhau như Cursor, Windsurf, Claude Code
- Triết lý đánh giá công cụ AI
- Trong hệ sinh thái công cụ thay đổi nhanh, trải nghiệm trực tiếp là điều bắt buộc
- Chỉ khi các thành viên trong nhóm áp dụng AI vào code thực tế hằng ngày và tự tạo, tự dùng cả các tệp cấu hình agent thì mới có thể biết được hiệu năng
- Việc đánh giá kết hợp chỉ số khách quan (mức sử dụng, hiệu năng) và khảo sát chủ quan (mức độ hài lòng về DX)
- Hiệu quả và giá trị cảm nhận được
- Các kỹ sư cảm thấy AI giúp tìm kiếm tài liệu, tóm tắt, hiểu code dễ hơn và giảm tải nhận thức
- Trong thị trường nhân tài cạnh tranh, nếu không cung cấp công cụ tốt nhất thì có nguy cơ mất lập trình viên → bản thân việc cung cấp công cụ đã là một chiến lược giữ chân nhân tài
- Khó khăn trong đo lường
- Các con số do vendor cung cấp chỉ dừng ở những chỉ số hạn chế như tỷ lệ chấp nhận, rất khó nắm được tác động kinh doanh thực sự
- Việc xác minh chính xác bằng A/B test cũng gần như không khả thi trong thực tế
- Khó tổng hợp dữ liệu sử dụng từ nhiều công cụ khác nhau (GitHub, Gemini, Slack, Notion, v.v.) → giới hạn telemetry và vendor lock-in là rào cản chính
- Kết quả là hiện tại cảm nhận của lập trình viên vẫn là tín hiệu chủ đạo
- Những mảng hoạt động tốt
- Đạt kết quả lớn trong migration: cảm nhận giảm được 40~60% khối lượng công việc thay đổi code
- Với các tác vụ lặp lại và thủ công như ghi chú cho data model, LLM sẽ soạn bản nháp đầu tiên, kỹ sư chỉnh sửa lại → tiết kiệm lao động ở quy mô lớn
- Bài học ngoài dự kiến
- Thiếu cảm nhận về chi phí LLM: nếu trực tiếp nhìn hóa đơn theo lượng token sử dụng thực tế, mọi người sẽ cảm nhận rõ hơn nhu cầu tối ưu hóa
- Ví dụ: tính năng review code tự động của Copilot tiêu tốn nhiều token nhưng hiệu quả thấp, nên mặc định bị tắt và chuyển sang cơ chế opt-in khi cần
- Những mảng không dùng AI
- Liên quan đến dữ liệu khách hàng: cấm áp dụng AI cho cả dữ liệu gốc lẫn dữ liệu đã khử định danh
- Trong các khu vực dữ liệu nhạy cảm, ưu tiên cao nhất là ngăn ngừa rủi ro rò rỉ dữ liệu
- Triết lý của đội nền tảng
- Cung cấp guardrails: tạo môi trường sử dụng an toàn như bảo vệ dữ liệu
- Chia sẻ trường hợp sử dụng: công khai minh bạch các ca thành công/thất bại và kinh nghiệm dùng prompt
- Nhấn mạnh tính hai mặt: chia sẻ cả mặt tích cực lẫn tiêu cực để duy trì góc nhìn cân bằng
- Nhắc lại giới hạn của LLM: AI cũng có giới hạn như con người nên không được quá tin tưởng
Kết luận và hàm ý
- Đo lường tác động của AI vẫn là một lĩnh vực rất mới
- Trong ngành vẫn chưa tồn tại “phương pháp luận tốt nhất”
- Ngay cả các công ty có quy mô và thị trường tương tự như Microsoft hay Google cũng dùng những chỉ số khác nhau
- Mỗi công ty đều có cách làm riêng và “flavor” riêng
- Việc đo đồng thời các chỉ số xung đột nhau là điều phổ biến
- Ví dụ điển hình: cùng theo dõi tỷ lệ lỗi sau thay đổi (độ tin cậy) và tần suất PR (tốc độ)
- Triển khai nhanh chỉ có ý nghĩa khi không làm tổn hại đến độ tin cậy, vì vậy cần đo lường cân bằng cả hai trục
- Đo lường tác động của công cụ AI là bài toán khó tương tự đo lường năng suất lập trình viên
- Đo lường năng suất là vấn đề mà ngành đã vật lộn hơn 10 năm
- Không thể dùng một chỉ số đơn lẻ để giải thích năng suất của cả đội, và việc tối ưu theo một chỉ số cụ thể cũng không đồng nghĩa năng suất thực sự tăng lên
- Năm 2023, McKinsey tuyên bố đã “giải quyết” được cách đo năng suất, nhưng Kent Beck và tác giả bài viết tỏ ra hoài nghi → bài phản biện
- Dù chưa có lời giải rõ ràng, việc thử nghiệm vẫn cần thiết
- Chừng nào bài toán đo lường năng suất còn chưa được giải quyết hoàn toàn, việc đo lường tác động của công cụ AI cũng khó có thể được giải quyết trọn vẹn
- Dù vậy, vẫn cần tiếp tục thử nghiệm và thử các cách tiếp cận mới để trả lời câu hỏi “Công cụ coding AI đang thay đổi hiệu quả làm việc hằng ngày/hằng tháng ở cấp độ cá nhân, nhóm và công ty như thế nào?”
Chưa có bình luận nào.